
Graph Schema Design: The Water We All Swim In
We recently had the pleasure of hosting Max Latey, CEO and founder of Pinboard Consulting, to discuss something that's been coming up a lot lately: property graph schemas. If you've been following the GraphGeeks Discord, you've probably seen Max dropping insightful observations about property graphs, and we wanted Max to share his wisdom with a broader audience.
Max opened with a memorable analogy about two young fish who meet an older fish. The older fish asks, "How's the water?" and after he swims away, one young fish turns to the other and asks, "What the hell is water?"
That's exactly what schemas are in the graph world – they're the water everyone swims in. Even foundational texts in network science rarely show schemas explicitly, instead assuming readers will intuit the underlying structure. The "OG schema," as Max calls it – a thing related to a thing with a self edge – is everywhere, yet it's rarely where the teaching of graphs begins.
The Deceptively Simple Side-by-Side Method
In the discussion, Max shared something that really changes how you can approach creating schemas. He introduced the "side-by-side method" – showing a schema diagram alongside an example graph that implements that schema. Schema on the left, dotted line in the middle, actual graph instance on the right. This approach makes a lot of sense, and frankly, everyone should be doing this.
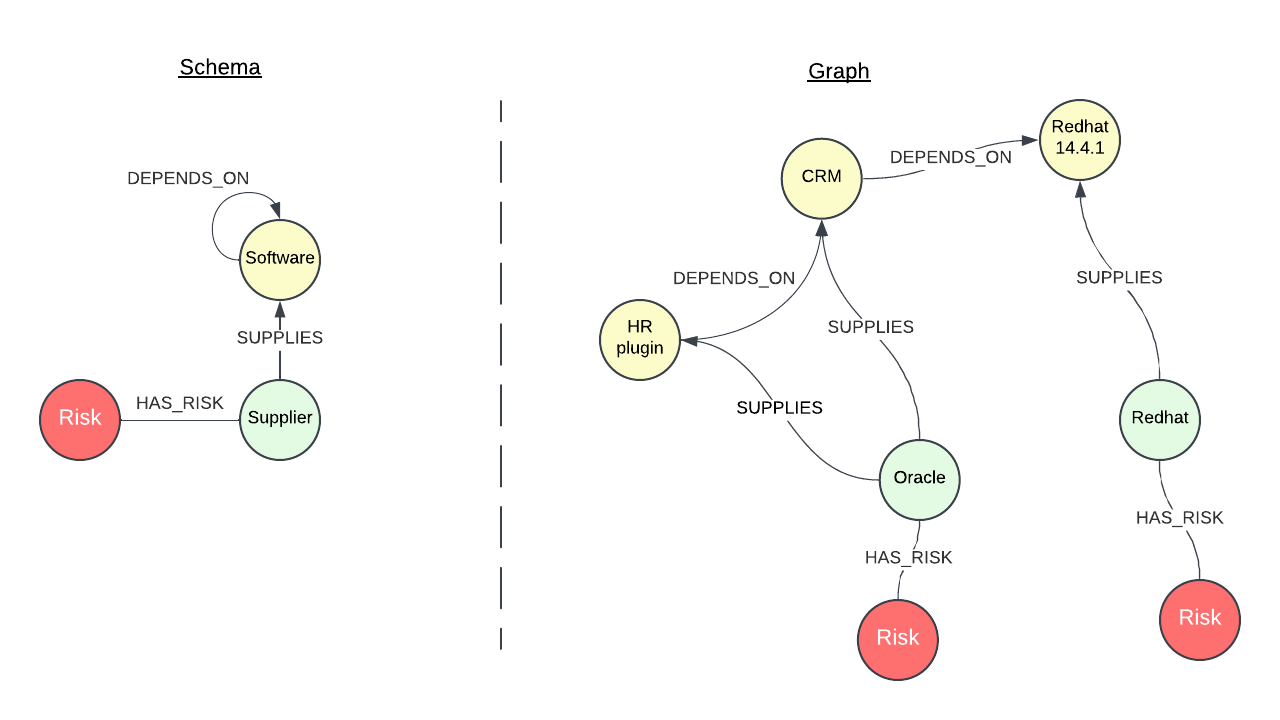
We’ve all seen both approaches used separately. Usually, the schema is shown because that's the technical detail being implemented. Then inevitably someone asks, "But what would it look like if we had this scenario?" and someone sketches out an example. Max realized these conversations were happening over and over again, so why not be explicit from the start?
The engagement and comprehension he gets from clients using this method are remarkable. It eliminates those dangerous assumptions where people think they're on the same page, but they're actually talking about completely different things. Some people can think in schemas and imagine a graph. Others can think in graphs and imagine a schema. But doing them side-by-side reinforces both and dramatically improves understanding.
Good, Bad, and Ugly Schema Design
Max's breakdown of schema design quality was fun and eye-opening. He showed examples of genuinely bad schemas – ones where experienced graph practitioners can just squint and immediately know something's wrong. Too many node types, no self edges, long chains of node-edge-node-edge patterns that look problematic.
But here's where the business impact really shows: when a well-designed graph schema is put in front of business users, they immediately recognize their domain. They lean in and say, "That's where my production order is!" They're not just talking about data and tables anymore – they're talking about their business, their processes, their actual work. Graph schemas have this unique logical modeling power that makes complex business relationships intuitive and accessible.
The beautiful thing is that graph technology is really good at handling schema changes. It's much easier to refactor a graph schema than to restructure a relational database when the understanding of the domain evolves.
The Challenges Ahead
We also discussed some of the open challenges in the schema space. Schema management is still a huge gap in the graph technology landscape. Most graph databases have minimal schema management tools – no real version control, no collaboration, no integration with CI/CD pipelines. There are some emerging tools like Graph.Build and Hackolade that are stepping up, but it's still an area that needs development.
Max also touched on cardinality constraints as another interesting challenge specific to graphs. In traditional databases, one doesn't often worry about how many relationships of a particular type a node can have. But in graphs, this becomes crucial for data integrity. We even discussed an example around permission systems where allowing unlimited relationships of a certain type could accidentally violate security protocols.
Looking Forward
What excites Max most about 2025? Awareness and adoption. The graph world is still relatively small and needs to grow. But with SQL:2023 including GQL, Google’s BigQuery graph capabilities, and other hyperscalers getting involved, there's a democratization of graph thinking underway.
The goal isn't to make everyone a graph expert – it's to help people recognize when they have "thing related to thing" data and understand that there might be a better way to work with it than traditional tabular approaches.
Max's passion for making graph concepts accessible is clear. By being more explicit about schemas, using techniques like the side-by-side method, and focusing on that logical modeling power, more people can be helped to see the water they're swimming in.
Ready to transform how you think about graph schemas?
Dive deeper by watching the complete recording of Max's webinar here. For ongoing insights and direct engagement, join the conversation and connect with @maxlatey in the GraphGeeks Discord.