
What Every Developer Needs to Know About In-Process DBMSs: Relational, Vector, and Graph Use Cases

SQLite, the mother of all in-process (aka embedded, embeddable, or serverless) DBMSs, has been wildly popular for over two decades. SQLite is, in fact, the most popular DBMS in the world by the number of deployments: over 1 trillion according to this article! So, in-process DBMSs are hardly new. Yet, starting with DuckDB and later with Kuzu and LanceDB, there has been a renewed interest in using in-process DBMSs within a wide range of data-intensive application domains: relational analytics, graph querying and analytics, and vector search. As a co-founder of Kuzu Inc., the team behind the Kuzu graph DBMS, I get asked a lot of questions about this new generation of in-process databases, such as:
What are the advantages and disadvantages of in-process DBMSs?
What are their common use cases (we'll focus on graph use cases)?
Does "in-process" mean the databases are ephemeral? (Short answer: No--but many offer an "in-memory" mode where databases are ephemeral)
Does "in-process" mean it can only handle small data? (No!)
What do I do if my application requires a DBMS server?
My goal in this post is to answer these questions and help developers understand where in-process DBMSs fit in contrast to traditional client-server ones. My example use cases use Kuzu, so I hope I can also showcase when graph applications can benefit from in-process DBMS.
In-process vs. Client-server is a Deployment Feature
The most important takeaway from this post is this: the difference between in-process and client-server DBMSs is primarily about deployment. In-process DBMSs are libraries that are statically imported in a host application. That is, the DBMS software is bundled together with the application in a single OS process (hence the term "in-process"). Therefore, in-process DBMSs are used just like how data science libraries such as Pandas or NetworkX, are used. This contrasts with client-server DBMSs, such as Postgres, MySQL or Neo4j, which run as separate server processes with which your (client) application communicates through a network protocol. The following figure demonstrates this difference:

To demonstrate how in-process DBMSs are used, consider an application code that asks a Cypher query using Kuzu:
import kuzu
db = kuzu.Database("./demo_db")
conn = kuzu.Connection(db)
res = conn.execute('MATCH (a:User)-[f:Follows]->(b:User) RETURN *')
Here, when the process running the application executes the conn.execute('MATCH ...') line, the Kuzu software code starts executing, evaluates the query, and passes back the results directly to the application code. In contrast, in a client-server DBMS, a separate DBMS server process runs somewhere else and waits for queries. The application process sends the query to the DBMS server using a network protocol. The DBMS server receives and evaluates the query and sends the results back to the application over the network.
In light of this difference, in-process DBMSs have two appealing features:
Simplicity: In-process DBMSs are very easy to get started with and use. Many of the typical setup steps required by client-server systems are completely eliminated:
No server maintenance: In-process DBMSs automatically start and shut down with your application. You don't need to set up, configure, start, stop, and maintain a separate DBMS server process.
Installation: Installing an in-process DBMS is often as simple as running a "pip install" or "npm i" command followed by an import statement in your application. You do not need to reach out to server admins to get root permissions or master complex server configuration files. If you can run your application, you can run an in-process DBMS.
No DBMS-level user/password authentication: In-process DBMSs often don't natively require any user authentication steps, such as setting up users, groups, passwords that are specific to the DBMS. If you want to manage who can access the contents of your database records, you can manage this at the file system level. In-process DBMSs persist the databases as files on disk. If you don't want user Alice to read or write to a database, you can set the file system permissions on those database files or directory to limit any process that Alice runs to not read or write to those files. If your databases are stored in the cloud, say in S3 buckets, then you can use the cloud provider's IAM permissions to manage necessary access permissions.
Versatility in application architectures: In-process DBMSs can be deployed pretty much anywhere. You can put them into your Python scripts, into your AWS lambda functions, your iPhone and Android phones, and even into your browsers (see SQlite-Wasm, DuckDB-Wasm, and Kuzu-Wasm). This has a very important consequence -- you can develop data-intensive applications anywhere using in-process DBMSs. I highly recommend listening to Hannes Mühleisen's (co-creator of DuckDB) "Going Beyond Two-tier Data Architectures" talk where he articulates this point very nicely. "Two-tier" refers to application architectures that use client-server DBMSs, which limit how and where data can be processed. With in-process DBMSs you don't have to move your data into another process in order to do something with it. For example, you can analyze your data at the location it resides, e.g., directly in a browser or inside a car's Android system without sending data to the cloud. This can be critical for privacy and performance.
In short, in-process DBMSs aren't scary, monolithic systems that require constant maintenance and database administration. Instead, they are DBMS libraries that can be deployed anywhere -- giving you a lot of flexibility in how you architect your data-intensive applications. In fact, you can often observe that users of in-process and client-server DBMSs refer to different things when they use the word "database." When a Postgres user refers to a Postgres database, they're usually talking about the DBMS server running somewhere. In contrast, a SQLite user referring to a SQLite database usually means the actual file on disk, similar to how they refer to a parquet or CSV file, since there is no separate "SQLite software" running somewhere. Thinking of databases as files that your applications generate and share with each other may take getting used to, but it can lead to much simpler ways of architecting your data-intensive applications.
Aside from the above two advantages, in-process DBMSs can also have performance advantages:
Performance advantages: In-process DBMSs make moving data between the database and your application very cheap — sometimes even zero-cost. This also extends to interactions between the DBMS and other libraries your application uses. For instance, DuckDB and Kuzu can directly scan Pandas or Polars data frames, which are in-memory Python objects, without any copying or serializing costs (see DuckDB docs and Kuzu docs). Let’s extend our earlier example using Kuzu in Python to illustrate how this works in practice:
import kuzu
import polars as pl
...
df = pl.DataFrame({
"name": ["Adam", "Karissa", "Zhang"],
"age": [30, 40, 50]
})
conn.execute("COPY User FROM df")
The COPY User FROM df is a Kuzu query that inserts the contents of df, which is a Polars data frame stored as an in-memory Python object. Since Kuzu also runs as part of the same Python process, it can directly access and scan the contents of the data frame without incurring any data movement costs, e.g., any serialization/deserialization or data copies.1
Does In-process Mean Databases are "Ephemeral"?
I'll next address a common misconception about in-process DBMSs. Because in-process DBMSs are Pandas or NetworkX-like data science libraries and because these libraries don't persist your data, a question I often get is: "Are the databases I create using in-process DMBSs also ephemeral?" The answer is: No! Just like any other DBMS, all the in-process systems I’ve mentioned—SQLite, DuckDB, Kuzu, LanceDB—persist your databases on disk. That said, many in-process DBMSs also offer an “in-memory” mode2 if you don’t want to persist your data. For example, in Kuzu, if you create a Database object with an empty string like this: db = kuzu.Database(""), you'll create an ephemeral database that is stored only in memory and not persisted on disk.
Although I don't know of any client-server DBMS that supports ephemeral databases, this is in principle possible3. The below picture summarizes how to think of (in-process vs client-server) and (ephemeral vs persistent) features of DBMSs. I've put a few example systems in their corresponding quadrants. DBMSs with both ephemeral and persistent modes I put across two quadrants4.

Does In-process Mean "Small Data?"
Another common question is: "Should in-process DBMSs be used to process small data?". This is in fact related to the previous misconception that in-process DBMSs only store your data in RAM so cannot manage databases that don't fit in your RAM. The answer is also no here. In fact, modern in-process DBMSs all pride themselves for also being able to handle very large databases. I will not say a lot about this because every DBMS vendor claims to handle very large databases, so you should test them yourself. However, the general point is that how optimized a system is to handle large databases or to handle some workloads depends on dozens of internal features the system implements, such as whether is the system columnar vs row-based or what type of transaction concurrency control mechanism it uses. It is not connected to whether the system is in-process or client-server.
There is however a caveat that I want to mention, which is that being in-process implies that the system is a single node system. So these systems are not like Spark SQL, BigQuery, or TigerGraph, which run on multiple compute nodes and can scale your databases horizontally.
Some Common Use Cases
I already mentioned that a unique use case of in-process DBMSs is that they can be deployed anywhere, e.g., AWS lambda functions, your phones, or browsers. So for graph users, you can build an on-device personal knowledge graph with Kuzu. You can even build a chatbot that retrieves facts through Graph RAG completely inside a browser (see details in this blog post). Let me give two examples (out of many others) to demonstrate some concrete application scenarios. I will continue picking my examples from Kuzu but similar scenarios exist for other in-process DBMSs (and see Hannes's talk for similar points).
Use Case 1: Component in a Large Data Processing Pipeline (Especially in Python)
Modern in-process DBMSs are very Python-friendly, which has become the prominent language for implementing data science and engineering pipelines. I also mentioned that these systems can seamlessly pass in-memory data objects from one library to another often without any data movement costs. This makes them very convenient to use in conjunction with other Python libraries, such as NetworkX, Pytorch Geometric, Pandas, Polars, Arrow, etc., as well as with each other (e.g., DuckDB and Kuzu). For example, Kuzu can directly scan Pandas, Polars, Arrow data frame objects, and output query results directly as data frames as well as NetworkX or Pytorch Geometric graphs. That allows the in-process DBMS to be used as a component of a larger pipeline that consists of multiple data libraries. Consider the below code as an example:
import kuzu
import pandas as pd
import networkx as nx
# Step 1: Perform some data transformation steps over some records using Pandas.
# ...
df = pd.DataFrame(data)
# Step 2.1: Write the Pandas dataframe contents to Kuzu (conn here is a Kuzu connection).
conn.execute("COPY User FROM df")
# ...
# Step 2.2: # Extract who-follows-whom subgraph since April 4th, 2025 into NetworkX.
G = conn.execute("MATCH (a:User)-[e:Follows]->(b:User) WHERE e.date > '2025-04-04' RETURN *").get_as_networkx()
# Step 3: Run PageRank graph algorithm in NetworkX. This assigns an importance score to each node.
prs = nx.pagerank(G)
# Step 4: Export PageRank results back to a Pandas dataframe.
pr_df = pd.DataFrame.from_dict(prs)
# Step 5: Write computed PageRank value of each node back to Kuzu.
conn.execute("LOAD FROM pr_df MERGE (u:User {pID: id}) ON MATCH SET u.pr = pagerank")
# ...
Note the seamless passing of Python objects in and out of Kuzu, which can directly scan in-memory Python data objects as well as output them in several formats (e.g., Pandas, Polars, NetworkX). This is what I mean by being very Python-friendly. This pipeline consists of 5 data processing steps that use 3 different libraries (Pandas, Kuzu, and NetworkX). The below figure summarizes the steps of the pipeline.

Use Case 2: On-demand Ephemeral Databases
Data-intensive applications generally build their databases upfront and ready to be queried when the demand appears. In contrast, applications can use in-process DBMSs to construct an ephemeral database on-demand, i.e., when the application requires it (recall that many in-process DMBSs have an "in-memory/ephemeral" mode). There are several scenarios when this is beneficial (see this blog post for a detailed case study). One common case is to create on-demand databases over a small subset of data from other large data sources. This case is especially common for graph databases because graph databases are often created by ingesting records from other tabular data sources.
Suppose you are working at a game company and one of your systems keeps track of the IPs users login from in a large Postgres database (say billions of records). Suppose another system collects daily information about each game each user was part of and stores a separate parquet file per-user in S3. Suppose a fraud detection application analyzes which IPs a user X has used, which other users have used similar IPs, and which games these users were part of. Specifically, let's suppose the application searches for graph patterns, e.g., cliques of users who participate in the same games and use similar IPs. As a solution, you can architect your system as follows:
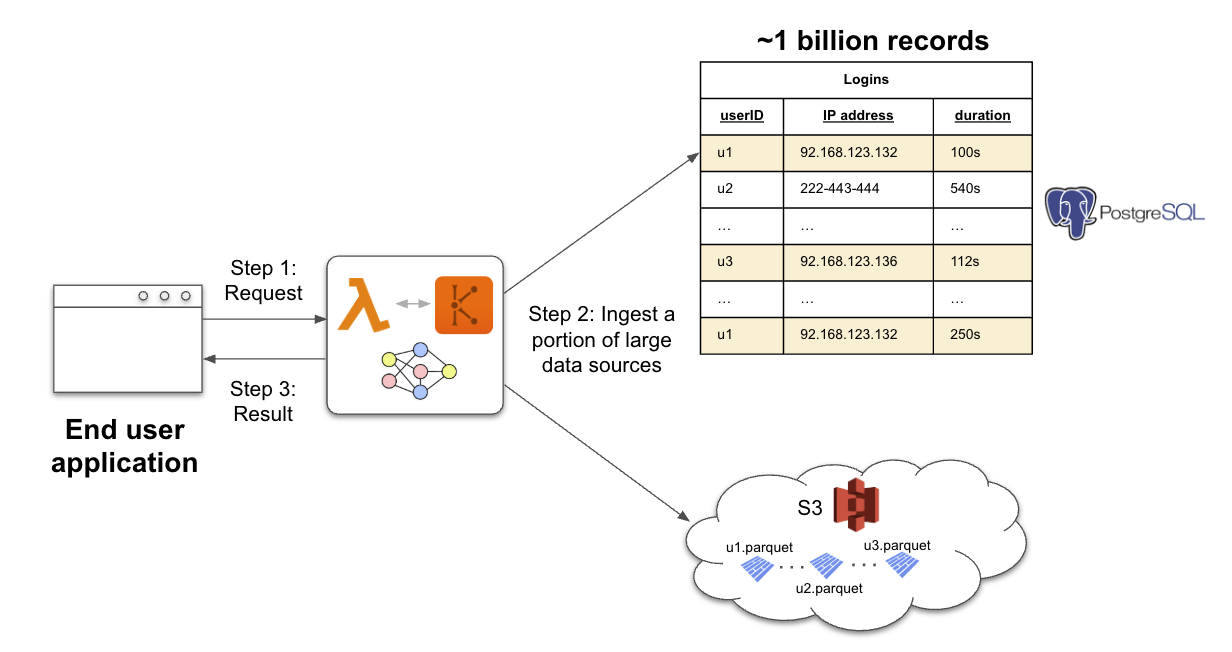
When the fraud detection application needs to search these patterns you spin off an AWS lambda function. The lambda function scans the data related to the suspicious user (u1 in the above figure) from Postgres and S3 and creates an ephemeral graph database in Kuzu5. Then the application searches for the graph patterns in Kuzu and sends the results of these graph queries back to the application.
This application architecture can have several benefits. First, the fraud detection application never maintains its own database server, so the architecture is simple and cheap. Second, the data in the fraud detection application is always up-to-date since they are scanned from the latest records available in the original sources when the data is needed. If databases were created up front, you would not have this guarantee. Third, we see users that have compliance reasons (e.g., EU privacy laws) that restrict them from creating large databases that co-mingle all users' data. Therefore, they need to create per-user smaller databases and instead of persisting and maintaining thousands of databases, they prefer to create them on-demand and throw them away.
What if You Need a DBMS Server?
Finally, there is an obvious shortcoming of in-process DBMSs, which is that sometimes applications need a DBMS server. For example, suppose you're building a browser-based online application where multiple users login to your website and for load balancing reasons, you need multiple Node servers to run and read and write to a central database. You would probably put an nginx server in front of these Node servers but let's ignore that for simplicity. The point is that you cannot embed an in-process DBMS in each of the Node servers. This is because each Node server is a different process and in-process DBMSs do not support multiple writes to happen to a database file from multiple processes. This is because for safe concurrency control, DBMSs need to coordinate concurrent writes. However, in this case there is no central DBMS software to coordinate the writes from different Node servers. Instead, each Node server in this scenario runs its own copy of the DBMS software, each of which wants to write to the same database file, but there is no central DBMS software to coordinate these writes. Therefore, you really need a client-server DBMS.
The common workaround to this scenario is to mimic a client-server DBMS architecture as follows. You wrap the in-process DBMSs around another API server, say a REST or FastAPI server and place this in front of the Node servers. The Node servers no longer embed the in-process DBMS and instead send their requests to the API server. Therefore, the API server takes the role of the DBMS server process in the client-server DBMS architecture. The workaround for this picture looks as below:

There are other cases when developers need a server and that is why some in-process DBMSs have a a server version of their DBMS either in the cloud or deployable on-premise, e.g., MotherDuck is the cloud version of DuckDB offered as a managed service.
Final Thoughts
I hope this post was helpful to position in-process DBMSs against client-server ones and clarify some of the misconceptions about them. For many applications, especially graph applications, which are often analytical in nature, using an in-process DBMS as a library instead of maintaining a DBMS server can significantly simplify your lives. Remember that in-process DBMSs are, first and foremost, DBMSs -- i.e., they provide all of the advanced features you expect from a DBMS, and they can be state-of-the-art in their performance and the amount of data they can manage. If you'll excuse a small plug, I encourage you to try Kuzu on very large graph databases and be impressed with its data ingestion and querying speed. As I mentioned above, being in-process is merely a deployment feature and should not be associated with how well-optimized the system is for some workload. Finally, the takeaway from this post should not be that in-process DBMSs can handle any workload and are suitable for any application. For many applications, some of which I covered above, they can be the right choice to use as the main DBMS. For other applications, they can also be useful to complement client-server ones.
Semih Salihoğlu
Associate Professor at University of Waterloo, Co-founder & CEO of Kùzu Inc.
Footnotes
There is of course the cost of converting the data from/to the format of one library to the format of the in-process DBMS. This is an inevitable cost. ↩
LanceDB seems to have an in-memory mode but as far as I can see this is not documented and they do not seem to encourage the usage of this aside from testing. There are some examples for using them in tests and an issue in their repo to document this. ↩
I should note that "in-memory" is a confusing term that means two separate things in database jargon. In the context of client-server systems, say SAP HANA, the term means that the DBMS always caches all of your records in memory in addition to persisting your data on disk. So SAP HANA databases are not ephemeral. In the context of in-process DBMSs, say SQLite, the term "in-memory" mode means that the databases are kept in-memory and they are also ephemeral, i.e., lost when your application shuts down. ↩
The figure assumes LanceDB only has a persistent mode. ↩
Instead of AWS lambda, this step can happen in a dedicated application process as well. ↩