
GraphFaker: Your New Tool for Graph Data
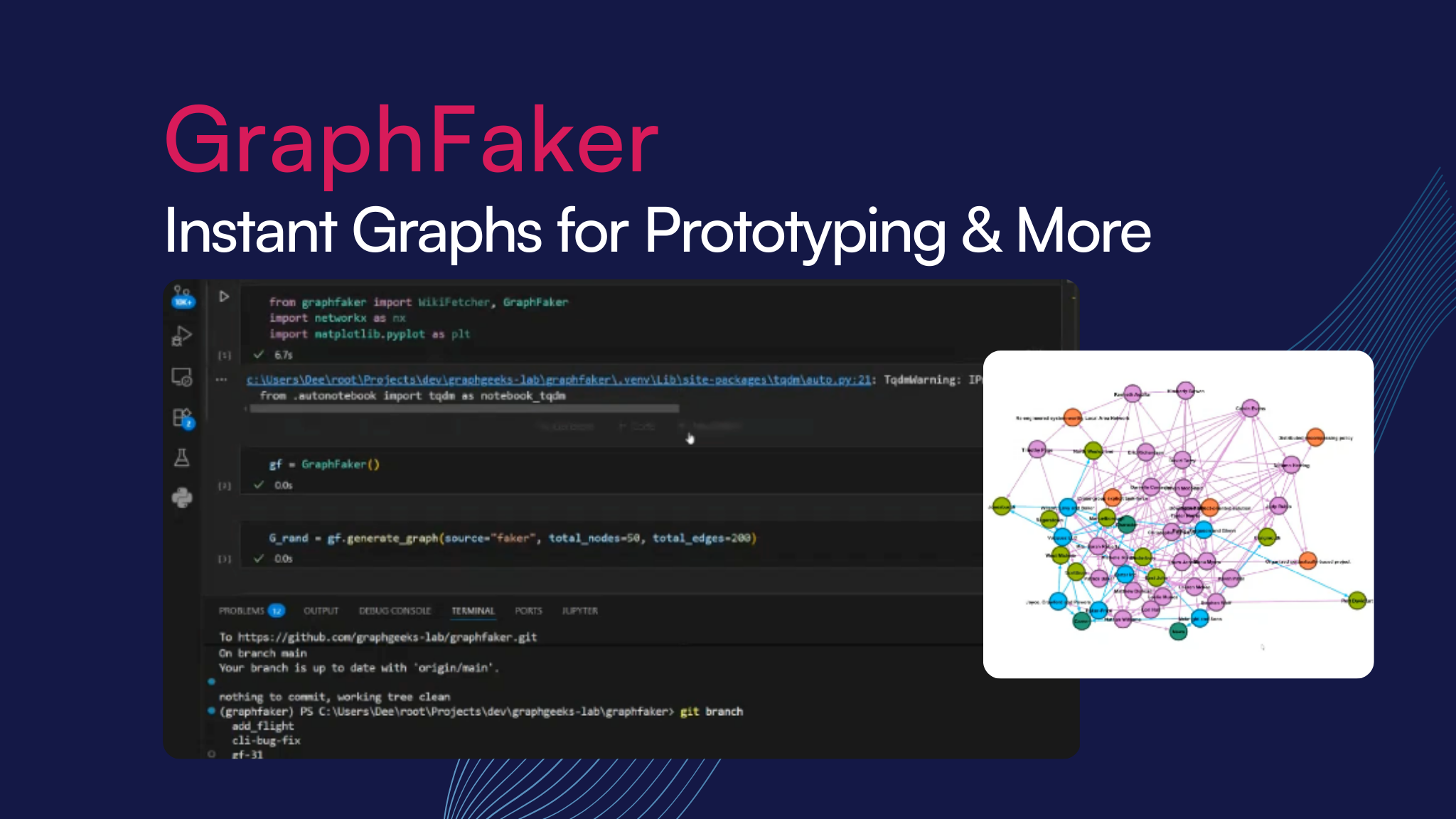
We’re delighted to share with the community our early progress on GraphFaker, an open-source Python library designed to improve how you work with graph data. As demonstrated by creator Dennis Irorere at a recent GraphGeeks talk, this tool aims to tackle some of the biggest pain points in the field: the difficulty of finding high-quality, realistic graph datasets and the time-consuming process of data preparation. GraphFaker is working on a solution for both, helping you prototype and test without the usual hassle.
The Problem: When Graph Data Isn't Ready to Go
Finding and preparing good graph data is notoriously difficult. As Dennis explained, his own journey with graphs during his master's program highlighted the challenges. You often have to deal with messy, proprietary, or privacy-sensitive datasets. The sheer amount of time spent cleaning and converting formats like CSV, Parquet, or JSON into nodes and edges can be a huge barrier, especially for beginners or those just wanting to test an algorithm.
The Solution: GraphFaker's Core Capabilities
GraphFaker is built on a simple but powerful idea: make creating graph data as easy as generating fake names with a library like ‘Faker’. It's designed to be a user-friendly and configurable tool for generating, loading, and exporting synthetic graph data. The library is currently in its early stages but already boasts several key features:
Faker: Generates synthetic "social-knowledge" graphs with rich attributes and relationships, including configurable sizes and weighted/directional relationships.
OSM (OpenStreetMap): Fetches real-world street networks, which can be done by place name, address, or bounding box. The topology can be simplified and projected to UTM.
Flights: Creates flight/airline networks using data from the Bureau of Transportation Statistics, including nodes for carriers, airports, and flights, and edges representing relationships.
WikiFetcher: Retrieves raw Wikipedia page data (title, summary, content, sections, links, references) ready for custom graph or RAG pipelines.
The library is an open-source project, with a current roadmap that focuses on improving documentation, enhancing export formats (specifically CSV and Parquet), and accepting community contributions for new datasets. The goal is to make it a heavy-duty, collaborative tool that addresses the needs of the wider graph community.
Try it for Yourself and Join the Conversation! 🤝
You can find the project on the GraphGeeks Lab on GitHub and install it directly from PyPl.
The project is in the early stages and the team wants your feedback. What features would you like to see? What kinds of datasets would be most useful to you? Whether you're a seasoned data engineer or just starting your journey with graphs, your input can help shape the future of this promising tool. You can find the project on GitHub and the Graph Geeks community on Discord to contribute or share your ideas. The goal is to build something truly useful for everyone working with graphs.